Interview Emile Vauge créateur de Traefik
Dec 16, 2018 22:26 · 2334 mots · 11 minutes de lecture

Bonjour Emile, est-ce que tu pourrais te présenter ?
Je suis développeur, je travaille depuis quelques années déjà et il y a 3 ans, j’ai travaillé sur un side project nommé Traefik, un reverse proxy écrit en Go, que j’ai open sourcé sur Github. J’ai ensuite créé une société, Containous, afin de poursuivre son développement.
Dans ton parcours tu as travaillé où ? Dans des startups, ESN, grandes entreprises ?
Tout à fait, j’ai travaillé dans diverses sociétés, comme Thales et Airbus et aussi de plus petites. Juste avant de lancer Traefik, j’étais chez Zenika où j’ai travaillé sur des sujets très divers et notamment dans le domaine de l’infrastructure.
Ton produit phare c’est Traefik, comment est-il né ?
C’était il y a un peu plus de 3 ans, à l’époque je travaillais à la mise en place d’une infrastructure microservice, plutôt complexe, puisqu’on devait pouvoir en déployer plusieurs milliers. A l’époque l’écosystème était encore tout frais, je suis parti sur Mesos/Marathon et Docker. Kubernetes n’était ni hype, ni stable. J’ai eu besoin de gérer le trafic réseau entre internet et ce cluster. Les reverse proxys traditionnels étaient difficiles à intégrer dans une plateforme hyper-dynamique comme la nôtre. Par dynamique je veux dire un système où l’on déploie très souvent de nouveaux services et où la configuration des reverse proxys est amenée à changer tout aussi souvent. Et c’est comme cela que j’ai eu l’idée de créer Traefik, un reverse proxy adapté à ces infrastructures très dynamiques.
C’est un produit qui était orienté docker au départ, mais vous vous êtes ouvert à plus de choses maintenant et c’est un produit qui continue d’évoluer ?
Oui, c’est un produit qui évolue vraiment très rapidement. A sa sortie il était compatible avec Mesos/Marathon, Docker, Consul, Etcd et nous avons ajouté le support d’autres orchestrateurs comme Kubernetes, Rancher et c’est en constante évolution. De part sa nature open source et communautaire, nous recevons beaucoup d’aide externe pour rendre le produit compatible avec de nouvelles solutions.
Comment gère-t-on justement une communauté aussi grandissante ?
En 3 ans nous sommes passés de zéro à plus de 19 000 stars sur Github, 400 millions de téléchargements et plus de 4000 personnes inscrites sur Slack. Le premier problème auquel on est confronté quand on travaille sur un logiciel open source, c’est l’afflux énorme d’information qui arrive tout le temps. Sur Slack, sur Github, par mail, des informations nous arrivent en permanence. Le gros problème c’est d’arriver à faire face, à trier et prioriser tout cela. Cela nous a pris un certain temps avant d’arriver à une situation stable [rire]. Nous avons dû mettre en place des processus, afin d’automatiser le plus de choses possibles sur le projet et éviter par exemple de passer trop de temps à trier des issues. Tout est automatisé au maximum, je donne un exemple, il n’y a plus besoin d’humain pour merger les Pull Requests (PR) sur Traefik. Tout est fait par un bot qui vérifie que toutes les conditions soient respectées avant de rebaser et merger les PR automatiquement. Parce qu’à un moment, nous avions tellement de PR ouvertes que nous passions trop de temps à les rebaser et à les merger, donc nous l’avons automatisé. Tout ça pour dire, que sur un projet comme celui là où les contributions externes sont nombreuses, on passe beaucoup de temps à gérer la communauté proprement dite et l’afflux de données qui en résulte.
Il y a beaucoup d’autres points qui sont particuliers lorsque l’on gère un projet open source, notamment la gestion de la roadmap. C’est toujours assez compliqué, il n’y a pas de réponse toute faite. C’est un subtile mélange dans lequel on ne peut pas prendre toutes les décisions de manière communautaire, sinon ça n’avance pas, mais pour autant il faut ouvrir la gouvernance de manière claire. On ne peut pas donner de recette toute faite pour bien gérer un projet open source, mais une des choses importantes, c’est que les mainteneurs, ceux qui ont un accès en écriture, ne soient pas que des employés de la société Containous. Depuis le début, l’équipe de mainteneurs a été ouverte à l’extérieur. Aujourd’hui, la moitié des mainteneurs sont dans la société et l’autre moitié sont externes. Les décisions importantes sont prises de manière collégiale et exposées au reste de la communauté. Ca permet d’être ouvert et transparent, mais également efficace.
Vous avez en effet bien grandi, si je ne me trompe pas tu étais seul à gérer le projet pendant presque 2 ans ?
Oui pendant 2 ans j’étais tout seul et aujourd’hui nous sommes 17 ! Nous sommes à présent distribués sur plusieurs villes et pays. L’équipe est présente à Lyon, Toulouse, Paris, en Belgique, en Pologne, au Canada et aux US. Containous est devenue internationale. On ne parle qu’en anglais. Bref, ca n’a plus grand chose à voir avec les débuts.
Une vraie success story, vous continuez de grossir, vous cherchez encore du monde ?
Oui nous continuons de grossir, nous cherchons particulièrement à nous étendre aux USA. Nous cherchons aussi bien en marketing qu’en commerce, mais nous recherchons bien sûr des gophers donc s’il y a des intéressés, il y a toujours des places ouvertes.
Traefik est écrit en Go d’où vient ce choix, tu as benchmarké plusieurs langages ou comment en es-tu venu à ce choix en particulier ?
C’est une bonne question. Je n’ai pas choisi Go forcément pour ses performances pures, sinon je l’aurais écris en C ou C++. Go étant garbage collecté, il y a déjà une barrière à ce niveau là. C’est pour l’écosystème très vaste et la rapidité de prise en main du langage et d’un projet écrit en Go. J’ai donc privilégié le fait d’être capable de s’interfacer avec énormément d’orchestrateurs et de Key-Value Stores qui sont pour beaucoup écrit en Go : Kubernetes, Docker, Consul, Etcd. De surcroît, pour un projet destiné à être open source et communautaire, entre le Go et le C, le ticket d’entrée n’est pas le même. Et je pense que c’est aussi une des raisons pour laquelle Traefik a beaucoup de succès, c’est tout de même relativement abordable de rentrer dans ce projet.
Et maintenant avec 3 ans de recul, pas de regret sur ce choix ? Est-ce qu’il y a des contraintes de Go qui vous pèsent aujourd’hui ?
Il y a en effet quelques contraintes, dont une particulièrement qui est en train d’être adressée, c’est la fameuse gestion des packages et dépendances. Ca été un peu Dallas pour ceux qui suivent ce sujet. Sur Traefik nous avons changé plusieurs fois de gestionnaire de dépendances depuis le début. Nous avons commencé avec Godep puis glide, maintenant nous sommes sur dep et nous allons passer sur les modules quand ça sera finalisé. Et je dois dire que nous avons vraiment perdu du temps avec ça. A partir du moment où le projet a grossi, et où nous avons commencé à avoir vraiment beaucoup de dépendances, nous avons eu quelques grosses traversées du désert.
Et second gros point noir, mais alors là c’était peut-être plus spécifique à notre projet, nous avons attendu pendant longtemps le support des plugins en Go. Il y a eu un premier effort qui a été fait pour les supporter en 1.8, avec une solution basée sur les librairies dynamiques. Malheureusement cela a plus ou moins été abandonné en cours de route par l’équipe Go, parce que très compliqué à finaliser techniquement. Du coup, on se retrouve avec une feature clairement pas utilisable, en tout cas pour faire ce qu’on voulait faire. Ca donc été un autre point décevant. Après il y a toujours du bon et du moins bon sur un langage, mais c’était en tout cas pour nous les 2 points les plus décevants.
Par rapport à sa constante évolution, tu as des choses à nous dire sur la roadmap future de Traefik ?
Alors il y a pas longtemps nous avons écrit un article sur notre blog, dans lequel nous faisions du teasing de nos sujets de travail en cours. Alors nous n’allons pas tout révéler maintenant, parce que c’est un petit peu trop tôt mais nous pouvons parler de certaines choses, et notamment le fait que nous sommes en train de réécrire le coeur même de Traefik pour la prochaine version. Ca a été un énorme travail (plusieurs mois avec une équipe de 4 personnes) et c’est encore en cours. Nous allons faire plus d’annonces sur cette partie là très bientôt, mais clairement il va y avoir des fonctionnalités importantes qui vont arriver à la suite de ce refactoring, dont évidemment une des features la plus demandée. Ceux qui suivent le projet devraient savoir de quoi il s’agit.
Et vous avez porté une attention à la rétrocompatibilité dans cette réécriture ?
Oui bien sûr, quand je dis que nous avons réécrit le coeur, ça ne veut pas dire que nous avons tout cassé [rire]. Pourquoi cette réécriture ? Parce qu’on en était arrivé à une limitation de l’architecture telle qu’elle avait été créée au départ et qui nous empêchait d’implémenter certaines fonctionnalités. Du coup nous avons préféré ne pas continuer avec cette architecture vieillissante. Cette nouvelle version est également bien plus facilement maintenable. En bref, nous mettons en place la base pour les 5 prochaines années, tout en gardant une compatibilité avec l’architecture actuelle.

Quel est ton regard sur la communauté des gophers en France ? Tu en côtoies pas mal, tu participes à de nombreux événements, quel est ton ressenti sur cette communauté et sur la façon dont Go est en train de prendre chez nous ?
C’est marrant parce que je constate qu’en quelques années seulement, ça a beaucoup évolué. Je me rappelle quand j’ai commencé à faire du Go, et encore je n’étais pas un gopher de la toute première heure, c’était assez confidentiel, il n’y avait vraiment pas beaucoup de gens qui en faisait dans mon entourage, et clairement pas dans un environnement professionnel. Aujourd’hui, on rencontre de plus en plus d’entreprises qui en font, ça permet au langage de percer. On sent vraiment que le langage prend sa place dans le monde professionnel. C’est encore jeune mais les mentalités changent. L’arrivée d’une gestion des dépendances officielle va probablement accentuer cette adoption dans les entreprises.
Mon petit doigt m’a dit que tu avais encore une petite annonce à nous faire, tu nous as déjà parlé de la réécriture, mais de quoi pourrais-tu encore nous parler ?
Aujourd’hui Traefik est un produit utilisé par beaucoup d’entreprises en production, sur des infrastructures importantes. C’est devenu un projet qui fait partie du paysage des plateformes microservices. Après plus d’un an de travail et de challenges techniques, nous sommes très fiers d’annoncer la disponibilité de Traefik Enterprise Edition en Early Access.
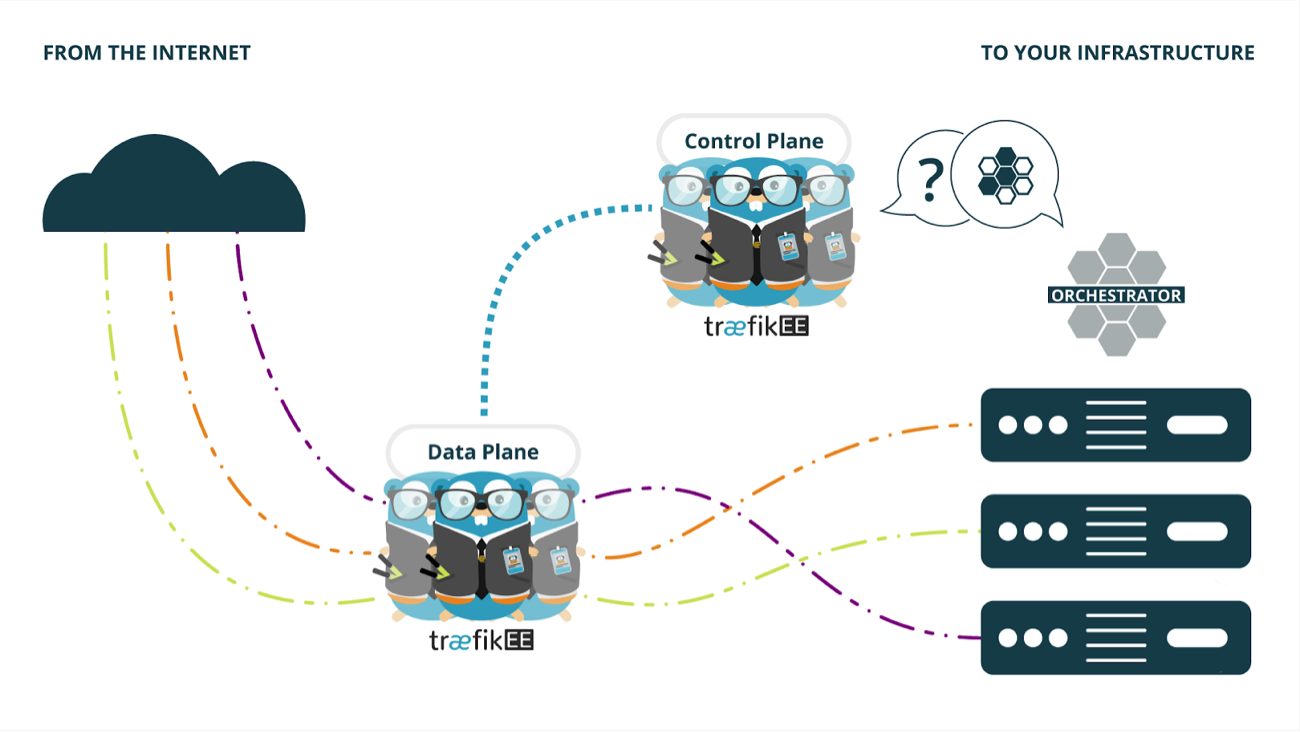
Qu’est-ce que Traefik Enterprise Edition ? Il s’agit d’une surcouche de Traefik, permettant à plusieurs serveurs de se connecter en cluster, basé sur un consensus Raft. Là où ça devient intéressant, c’est que tout ceci est implémenté par TraefikEE directement, sans nécessité d’outil externe (comme un Key-Value Store). Il devient donc possible de déployer 3, 5 ou 10 instances de Traefik très simplement, partageant la même configuration de manière automatique.
Un cluster TraefikEE se compose d’un data-plane et d’un control-plane. Les noeuds TraefikEE du data-plane sont chargés du travail de forwarding des requêtes vers les serveurs backends. Les noeuds du control-plane forment un consensus Raft, tolérant aux pannes. Ils sont chargés du discovery des serveurs backends en étant connectés aux orchestrateurs/service-discovery. Ils sont également chargés de générer la configuration de routage et de l’envoyer au data-plane.
Cette architecture apportent plusieurs choses très intéressantes. Premièrement, la haute disponibilité. En cas de perte d’un des noeuds du control-plane, la configuration ou les certificats ne seront pas perdus car répliqués sur les autres noeuds. En cas de perte d’un noeud du data-plane, les requêtes pourront continuer d’être traitées par les autres noeuds sans indisponibilité de service. La scalabilité sera également un point fort apporté par cette architecture. Le nombre de noeuds du data-plane pourra être adapté en temps réel en fonction des besoins. Et bien sûr, la simplicité de Traefik reste le point fort de cette version Enterprise, avec l’arrivée d’une CLI traefikeectl, qui permet de déployer et gérer en une ligne de commande un cluster complet sur votre infrastructure (comme Kubernetes ou Swarm par exemple).
En résumé c’est un produit unique en son genre, c’est le seul reverse-proxy au monde à être déployé nativement en mode cluster, ce qui apporte la tolérance aux pannes, scalabilité, tout en gardant la simplicité d’utilisation de Traefik. L’équipe est vraiment super fière de ce que nous avons accompli.
Bravo pour tout ce travail, on a hâte de découvrir tout ça !
Oui pour nous ça été un énorme travail, la moitié de l’équipe travaille sur ce projet, mais une chose est à souligner : le projet open source Traefik reste notre priorité absolue. Nous sommes justement en train de faire un gros travail sur la version open source et c’est clairement pour apporter des features qui sont attendues depuis longtemps par l’ensemble de la communauté. Pour résumer, nous proposons aujourd’hui une version Enterprise du projet Traefik, mais notre coeur de métier, nos aspirations profondes restent centrées sur le développement ouvert et libre.
Une dernière question avant de nous quitter, c’est quoi le délire sur le versionnement par nom de fromage ?
Évidemment [rire]. Je me rappelle qu’on en parlait avec les collègues et on se disait que ça serait bien de trouver des noms de version décalés. Le fromage est sorti au détour d’une conversation et on s’est dit qu’on tenait quelque chose. C’est drôle, français et ça n’a mais alors rien à voir avec l’informatique. En plus c’est inépuisable, avant d’arriver au bout des fromages français, on a le temps de faire quelques releases [rire].